I’ve been doing infrastructure for the past 15 years in many different roles – user, architect, partner, OEM pre-sales, etc across Windows, Linux, Servers, Virtualization, Storage, Backup, BC/DR and Hyperconverged Infrastructure. It was fun, fast moving and was solving a lot of fun problems. However, recently I’d found myself wanting to solve other problems that infrastructure just wasn’t or couldn’t. I was also looking for a whole sale change to really push me out of my comfort zone, to mix things up, while still staying in technology and getting in pretty early into a start-up. And honestly, I love change. Big change. I was pretty comfortable with the technology sphere I was working in and could have stayed on that path, which meant I should probably not :)
As we used to say at SimpliVity, “It’s all about the data”. And we were right. But, the manner in which we talked about ‘the data’ was block based. As I’ve been seeing the changes in how business run, expand and learn from their data, I’ve seen a lot of challenges that couldn’t be addressed with just housing and moving (or not moving, in the case of SimpliVity’s DVP) the blocks of data. This year’s X is faster, bigger, cheaper than last year’s. I wanted to solve challenges with the data itself. How do we access, connect, use, protect, govern, and free the data in a world of lakes and pools (data in MSSQL, NoSQL, Parquet files in S3 buckets, Hadoop, etc.), GDPR, Cambridge Analytica, PIPL, and a whole host of data regulations. If data truly is the ‘new oil’, that’s where I wanted to be.
Enter a conversation with Immuta, Inc, a company built out of data management in the Intelligence Community, specifically as it relates to access for data scientists for analytics and ML and its intersection of highly regulated data. How can analytic models be built on data that’s so heavily gated without getting in the way of time to value? How can we guarantee privacy with specific access intent? How can this be done no matter the data source? Great questions! Some I was thinking of, many I was not. Connectedness and governance, for Data Scientists, for regulated data, for ML. Now, the big question, how can we do this without copy data management hell? Without copying, and recopying and deidentifying, and copying again, then data for the model changes and the process repeats. How can we grant time and intent based 3rd party access to our data and guarantee auditable privacy?
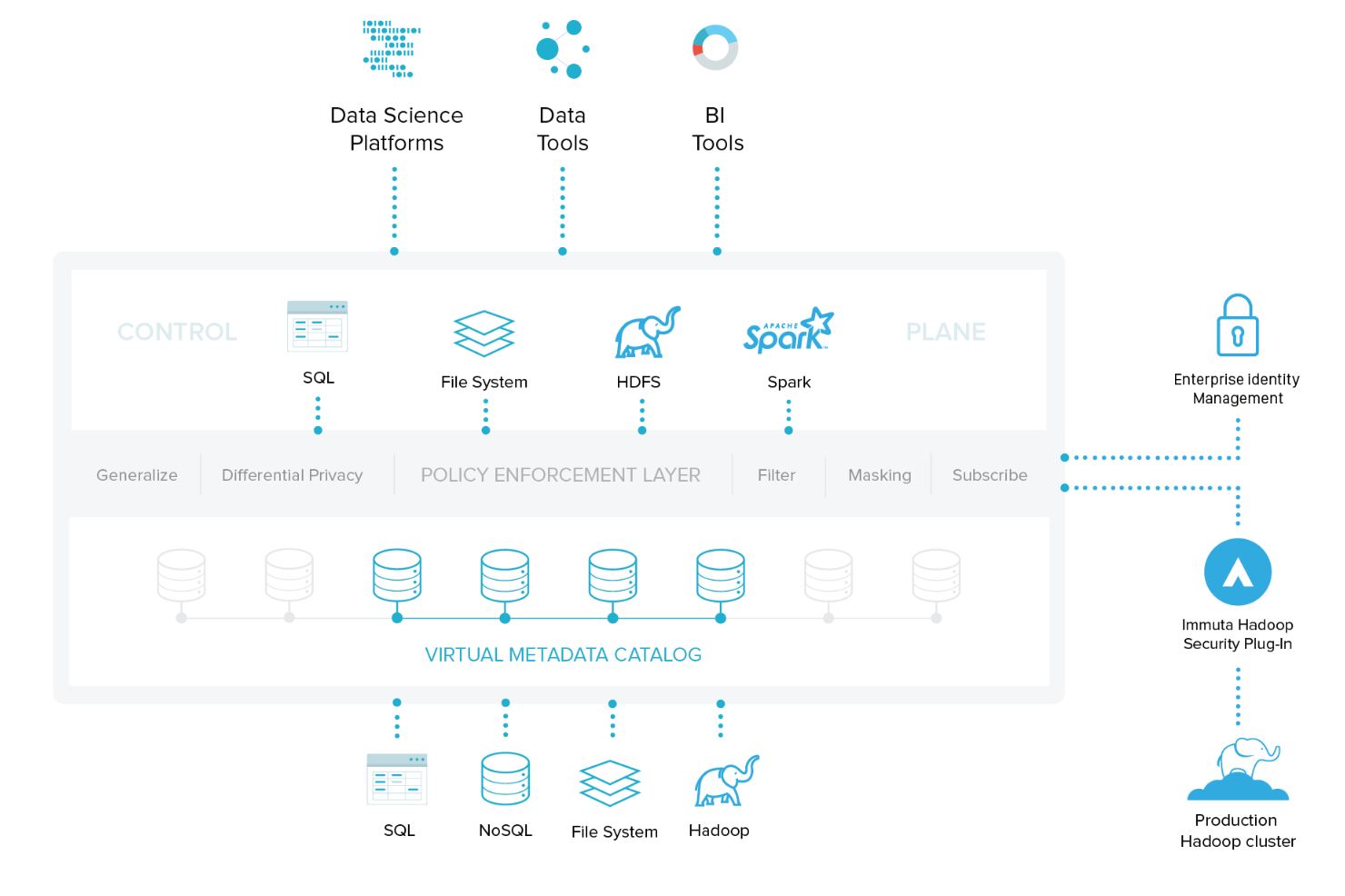
Immuta provides a common read-only data access interface. This is geared towards repeatable model training without requiring copy data management. And without having data science teams re-learn a new tool. They can use tools they already have for modeling and intelligence (e.g. Spark, Datarobot, Domino, H2O, Tableau, PostgreSQL, etc.) and join across them for cross data analytics. Data scientists get personalized access to data based on projects and subscriptions. Data owners get to grant self-service access to all their data types and services.
Then there is this amazingly rich policy engine for data governors and compliance teams, allowing them to create condition-based rules for data access through natural language filters. Data is hidden, masked, redacted, and anonymized on-the-fly in the control plane based on the attributes of the user accessing the data and the purpose under which they are acting. All of this done with granular audit controls and reporting (see the exact query by whom, when, under what access rule, etc.)
I’ve taken a role with Immuta as a Sr. Solutions Architect, tasked with helping build out their first Go to Market team. This decision didn’t come easy, as it means, mostly, farewell to the majority of my interactions with the virtualization and storage worlds. Of course, I’ve made some of my best friends there, so I’m not going away :) But it means less VMUGs, likely my last vExpert was 2018 and the like. Excited and a bit nervous of the degree of change ahead, but boy, am I looking forward to it.